NVIDIA启动PRORL方法:研究研究练习2000步,创建世
- 编辑:澳门新葡澳京官方APP -NVIDIA启动PRORL方法:研究研究练习2000步,创建世
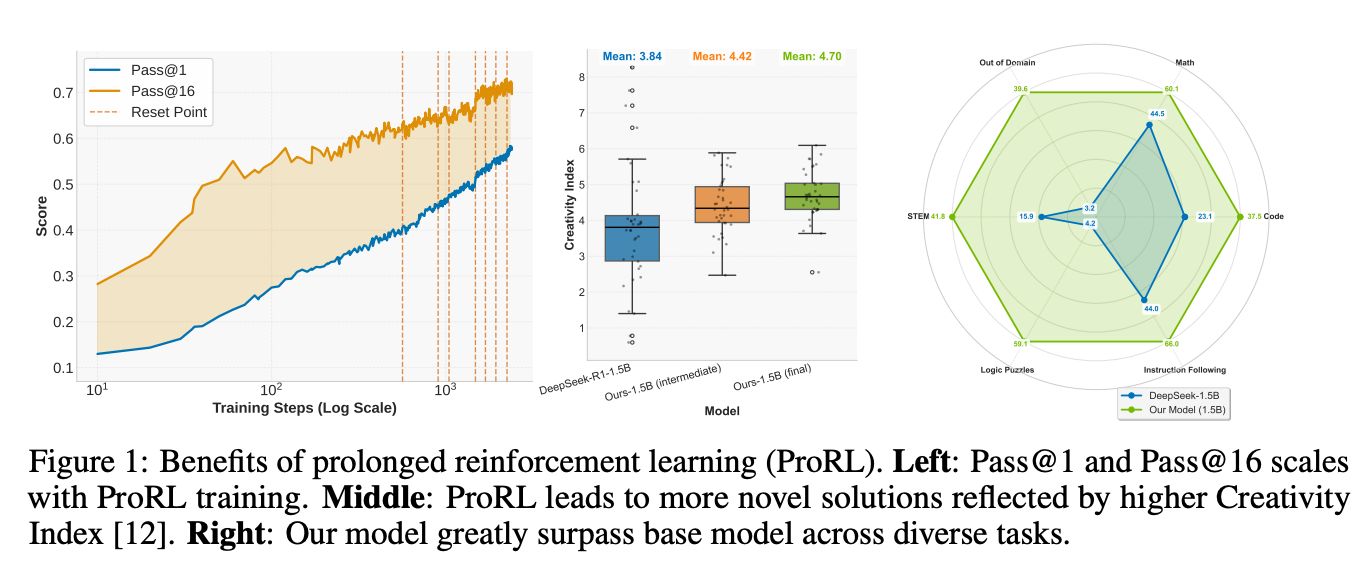 这是6月5日的新闻,技术媒体Marktechpost昨天(6月4日)发布了一篇博客文章,报道NVIDIA启动了Prorl的强化方法,并开发了最佳的1.5B参数推理模型,该模型是Nemotron-Research-Reasing-reasing-Qwen-Qwen-1.5B。背景简介推理模型是一个专业的人工智能系统,它通过详细的长链推理(COT)生成最终答案。研究结构(RL)扮演着非常重要的训练角色。 DeepSeek和Kimi之类的团队使用增强学习方法(RLVR)方法来促进算法,例如GRPO,Mirror Descent和Rloo。但是,研究人员仍在争论教育是否确实提高了了解大语言模型(LLM)的能力。现有数据表明,RLVR未能显着超出Pass@K指示器中的基本模型,该模型显示出识别能力的扩展有限。此外,当前的研究重点是特定诸如数学和模型之类的FIC领域通常被过度训练,从而限制了潜在的探索。同时,训练步骤的数量通常仅几百个步骤,这不允许该模型完全开发新的功能。 NVIDIA研究团队启动了Prorl的过程,PRORL方法的突破和应用解决了上述问题,该过程扩大了2,000多个步骤的加强教育时间,并在许多领域扩大了培训数据,例如数学,节目,程序,程序,STEM,STEM,逻辑,逻辑难题和教学合规性,覆盖136,000个例子。他们使用VERL框架和增强的GRPO方法开发了Nemotron-Research-Reaseering-QWEN-1.5B模型。这是对世界上1.5b参数的理解的最佳模型,它超过了DeepSeek-R1-1.5b的主要模型,而不是增长更大的DeepSeek-R1-7B。测试结果表明,该模型在数学领域增加了15.7%,编程任务通行证的准确性@1增加了14.4%,STEM推理和指令依从性分别增加了25.9%和22.0%,逻辑难题的奖励价值增加了54.8%,这是一种强大的能力。参考参考有房子
这是6月5日的新闻,技术媒体Marktechpost昨天(6月4日)发布了一篇博客文章,报道NVIDIA启动了Prorl的强化方法,并开发了最佳的1.5B参数推理模型,该模型是Nemotron-Research-Reasing-reasing-Qwen-Qwen-1.5B。背景简介推理模型是一个专业的人工智能系统,它通过详细的长链推理(COT)生成最终答案。研究结构(RL)扮演着非常重要的训练角色。 DeepSeek和Kimi之类的团队使用增强学习方法(RLVR)方法来促进算法,例如GRPO,Mirror Descent和Rloo。但是,研究人员仍在争论教育是否确实提高了了解大语言模型(LLM)的能力。现有数据表明,RLVR未能显着超出Pass@K指示器中的基本模型,该模型显示出识别能力的扩展有限。此外,当前的研究重点是特定诸如数学和模型之类的FIC领域通常被过度训练,从而限制了潜在的探索。同时,训练步骤的数量通常仅几百个步骤,这不允许该模型完全开发新的功能。 NVIDIA研究团队启动了Prorl的过程,PRORL方法的突破和应用解决了上述问题,该过程扩大了2,000多个步骤的加强教育时间,并在许多领域扩大了培训数据,例如数学,节目,程序,程序,STEM,STEM,逻辑,逻辑难题和教学合规性,覆盖136,000个例子。他们使用VERL框架和增强的GRPO方法开发了Nemotron-Research-Reaseering-QWEN-1.5B模型。这是对世界上1.5b参数的理解的最佳模型,它超过了DeepSeek-R1-1.5b的主要模型,而不是增长更大的DeepSeek-R1-7B。测试结果表明,该模型在数学领域增加了15.7%,编程任务通行证的准确性@1增加了14.4%,STEM推理和指令依从性分别增加了25.9%和22.0%,逻辑难题的奖励价值增加了54.8%,这是一种强大的能力。参考参考有房子

