决策能力增加了500%!通过微调语言模型技术的
- 编辑:澳门新葡澳京官方APP -决策能力增加了500%!通过微调语言模型技术的
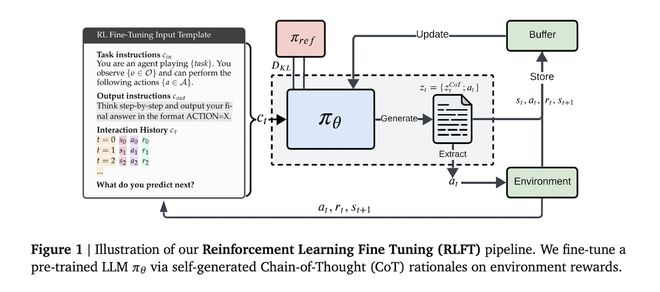 5月20日,技术媒体Marktechpost昨天(5月19日)发布了一篇博客文章,报道Google的DeepMind团队与John Kepllinz University的LIT AI实验室结合使用,提高了通过加强微调研究(RLFT)技术来决定语言模型的能力。它引用了一篇博客文章,并介绍了基于大量互联网数据训练的语言模型显示出了潜在的决策 - 制定文本处理,并且可以通过内部推理在交互式环境中做出行动选项。但是,这些模型在决策过程中存在重大缺陷:该模型可以减少正确的方法,但不能实施(了解Groniman),而较小的模型可以机械重复共同的动作(频率偏见)。尽管UCB算法等传统的增强方法可以平衡探索和使用,但它们很难解决该模型的固有行动 - 行动 - 行动 - 行动问题。 DeepMind团队现代是否使用模型的自我生成的链作为训练信号,采用微调技术的加强研究。该系统将检查与推理的每个步骤相对应的动作的回报,敦促模型优先级一致,实用,有效的动作计划。在特定实施过程中,该模型会根据输入指令和奖励行动历史记录生成一个序列,该序列包含认知和手势过程,并在蒙特卡洛的基准中优化了BYRI,并且对优势的一般估计。无效的行动将激发惩罚机制,奖励技术的技术不仅可以确保输出格式的规格,而且还保留了探索空间。在10臂的多臂匪(mab,带有n个拉杆的插槽机,拉动每个拉杆对应于奖励的可能性分布),2B参数模型的范围增加了12%年龄点;该改进很小,但在面对20臂时仍然很重要,其频率偏置率从70%降至35%。在TIC -TOE实验中,针对随机对手的获胜模型率增加了5次,而平均返回战斗与最佳的蒙特卡洛树搜索代理人是-0.95的零。值得注意的是,在27B大型模型中开发适当推理的可能性为87%,但是当不固定时,只有21%的人将执行最佳动作,并且这项加强研究在该领域有效地缩小了。 【来源:这在家】
5月20日,技术媒体Marktechpost昨天(5月19日)发布了一篇博客文章,报道Google的DeepMind团队与John Kepllinz University的LIT AI实验室结合使用,提高了通过加强微调研究(RLFT)技术来决定语言模型的能力。它引用了一篇博客文章,并介绍了基于大量互联网数据训练的语言模型显示出了潜在的决策 - 制定文本处理,并且可以通过内部推理在交互式环境中做出行动选项。但是,这些模型在决策过程中存在重大缺陷:该模型可以减少正确的方法,但不能实施(了解Groniman),而较小的模型可以机械重复共同的动作(频率偏见)。尽管UCB算法等传统的增强方法可以平衡探索和使用,但它们很难解决该模型的固有行动 - 行动 - 行动 - 行动问题。 DeepMind团队现代是否使用模型的自我生成的链作为训练信号,采用微调技术的加强研究。该系统将检查与推理的每个步骤相对应的动作的回报,敦促模型优先级一致,实用,有效的动作计划。在特定实施过程中,该模型会根据输入指令和奖励行动历史记录生成一个序列,该序列包含认知和手势过程,并在蒙特卡洛的基准中优化了BYRI,并且对优势的一般估计。无效的行动将激发惩罚机制,奖励技术的技术不仅可以确保输出格式的规格,而且还保留了探索空间。在10臂的多臂匪(mab,带有n个拉杆的插槽机,拉动每个拉杆对应于奖励的可能性分布),2B参数模型的范围增加了12%年龄点;该改进很小,但在面对20臂时仍然很重要,其频率偏置率从70%降至35%。在TIC -TOE实验中,针对随机对手的获胜模型率增加了5次,而平均返回战斗与最佳的蒙特卡洛树搜索代理人是-0.95的零。值得注意的是,在27B大型模型中开发适当推理的可能性为87%,但是当不固定时,只有21%的人将执行最佳动作,并且这项加强研究在该领域有效地缩小了。 【来源:这在家】

